All in N Ballin CS 175: Project in AI
Video Summary
Project Summary
Project “All in N Ballin’” focuses on creating an AI agent to play no-limit, heads-up Texas Hold ‘Em Poker. We are relying on an existing Python library, Google’s OpenSpiel, to utilize its existing poker implementation, help us create our training environment, and utilize its existing implementations of reinforcement learning algorithms. The goal for our project is to create a poker agent that reduces exploitability, and therefore approximates the Nash Equilibrium as close as possible. We are mainly using the Neural-Fictitious Self-Play (NFSP) reinforced learning algorithm to reduce exploitability in our agent.
Approach
The main algorithm we are using is Neural-Fictitious Self-Play (NFSP), described as “a deep reinforcement learning method for learning approximate Nash equilibria of imperfect-information games” (Heinrich and Silver 2020). NFSP is a hybrid between reinforcement learning and supervised imitation learning. The NFSP agents utilize reinforcement learning to train a neural network from game experiences against fellow agents to predict future moves, while also training another neural network off of its own moves against fellow agents utilizing supervised learning. From these two neural networks, agents “ cautiously [sample] its actions from a mixture of its average, routine strategy and its greedy strategy that maximizes its predicted expected value” (Heinrich and Silver 2020). NFSP is designed to optimize/minimize exploitability, for more information please refer to the Evaluation section on this page.
 Figure 1: NFSP Pseudocode
Figure 1: NFSP Pseudocode
The implementation of our agent relies on a custom Texas Hold ‘Em gamemode created with OpenSpiel’s universal_poker game to match the poker from our problem description. The specifics of our gamemode can be seen below:
CUSTOM_NO_LIMIT_HEADS_UP_TEXAS_HOLDEM_GAMEDEF = """\
GAMEDEF
nolimit
numPlayers = 2
numRounds = 4
raiseSize = 20 20 20 20
blind = 10 20
firstPlayer = 1
numSuits = 4
numRanks = 13
numHoleCards = 2
numBoardCards = 0 3 1 1
stack = 2000
END GAMEDEF
"""
Figure 2: Texas Hold ‘Em Gamemode OpenSpiel Parameters
From there, we utilized the example NFSP implementation from OpenSpiel’s source code to run on our Texas Hold ‘Em game. The inputs of our approach are the state of the game, including: each agent’s hole cards, the state of the board cards, the players’ turns to be dealer, the pool chip count, and their chip count. From the inputs, the agent determines the legal actions, and returns one of four valid moves, call, raise, fold, or check.
class NFSPPolicies(policy.Policy):
"""Joint policy to be evaluated."""
def __init__(self, env, nfsp_policies, mode):
game = universal_poker.load_universal_poker_from_acpc_gamedef(
CUSTOM_NO_LIMIT_HEADS_UP_TEXAS_HOLDEM_GAMEDEF
)
player_ids = [0, 1]
super(NFSPPolicies, self).__init__(game, player_ids)
self._policies = nfsp_policies
self._mode = mode
self._obs = {"info_state": [None, None], "legal_actions": [None, None]}
def action_probabilities(self, state, player_id=None):
cur_player = state.current_player()
legal_actions = state.legal_actions(cur_player)
self._obs["current_player"] = cur_player
self._obs["info_state"][cur_player] = (
state.information_state_tensor(cur_player))
self._obs["legal_actions"][cur_player] = legal_actions
info_state = rl_environment.TimeStep(
observations=self._obs, rewards=None, discounts=None, step_type=None)
with self._policies[cur_player].temp_mode_as(self._mode):
p = self._policies[cur_player].step(info_state, is_evaluation=True).probs
prob_dict = {action: p[action] for action in legal_actions}
return prob_dict
Figure 3: NFSP Implementation
Our NFSP implementation ran for three-million training steps, utilizing 128 neurons within the Q-net, and utilized the default hyperparameters within the NFSP algorithm in OpenSpiel. The hyperparameters were as follows:
- reinforcement learning rate: .01
- supervised learning rate: .01
- policy update every n steps: 64
Evaluation:
The main quantitative metric we are evaluating our agent by is exploitability, which is a measure of how “well a strategy profile approximates a Nash equilibrium” with “the closer it [being] to zero, the closer the policy is to optimal” (Timbers et. al, 2022). To measure our exploitability, we called OpenSpiel’s open_spiel.python.algorithms.exploitability.exploitability() function with our game tree along our policy class instances as parameters every ten–thousand training steps. This function would then return and log the exploitability. As seen in Figure 4, our agent’s exploitability continually reduced throughout the training steps, fluctuating between .01 and .02 towards the end, and marking ~ .015 exploitability on the final step.
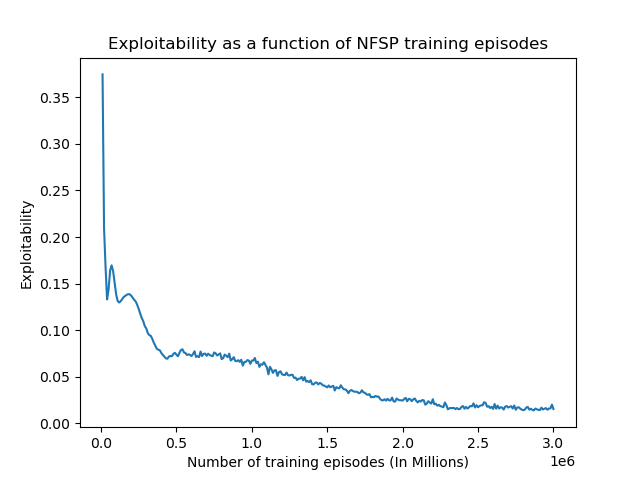 Figure 4: Exploitability of agents as a function of training steps
Figure 4: Exploitability of agents as a function of training steps
Another quantitative metric we tracked was the loss for both the supervised and reinforcement learning aspects of NFSP, for both agents that trained against each other. As seen in the figures below, the losses continued to fluctuate drastically throughout the training process, and neither the supervised or reinforcement learning losses converged. This is not of too much concern to us since the most important metric, exploitability, continues to decrease regardless of loss.
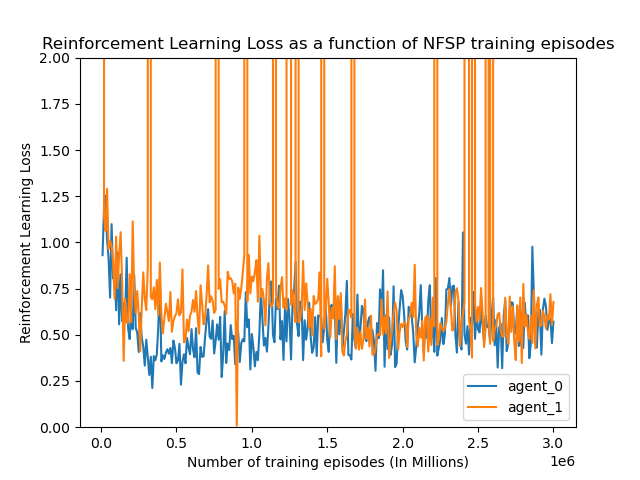 Figure 5: Reinforcement learning loss of agents as a function of training steps
Figure 5: Reinforcement learning loss of agents as a function of training steps
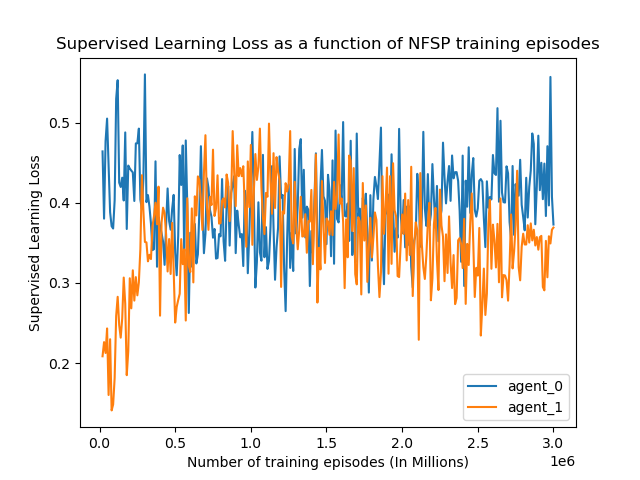 Figure 6: Supervised learning loss of agents as a function of training steps
Figure 6: Supervised learning loss of agents as a function of training steps
Remaining Goals and Challenges:
For the remainder of the quarter, our main goal is to further reduce the exploitability of our agent. We believe our prototype is still limited in its ability to approximate the Nash Equilibrium, and we believe we can further reduce our exploitability. Our plan until recently was to create a hybrid algorithm between NFSP and imitation learning, but we have already come across a few challenges for this idea. We briefly experimented with creating an imitation model that was trained using data from the Annual Computer Poker Competition, but found that getting enough data consistent with our specific version of poker to train the imitation agent on was a challenge, but more importantly we discovered that NFSP is itself already an imitation and reinforcement learning hybrid algorithm. This would make our former plan to improve this algorithm possible redundant and obsolete. For now, we are unsure on how to proceed, but we are meeting with the professor in a few days (from the time of writing this) for help. Once we have developed our own unique algorithm, we plan on comparing our agent to an unaltered NFSP agent, CFR agent, and an imitation agent.
Additionally, the loss we’ve observed is a little high, so that’s one area our model needs to work on. Our observations show that the loss doesn’t improve much after a certain point, and we’d like to see if we could bring down the loss even more, especially if there might be a positive correlation between loss and exploitability.
Resources Used:
Code Documentation:
OpenSpiel Source Code:
- https://github.com/google-deepmind/open_spiel/blob/master/open_spiel/python/examples/universal_poker_cfr_cpp_load_from_acpc_gamedef_example.py
- https://github.com/google-deepmind/open_spiel/blob/master/open_spiel/python/examples/kuhn_nfsp.py
OpenSpiel Algorithms:
- https://github.com/google-deepmind/open_spiel/blob/master/open_spiel/python/algorithms/nfsp.py
- https://github.com/google-deepmind/open_spiel/blob/master/open_spiel/python/algorithms/exploitability.py
Scientific Reports:
- https://www.davidsilver.uk/wp-content/uploads/2020/03/nfsp-1.pdf
- https://www.ijcai.org/proceedings/2022/0484.pdf
Libraries:
- OpenSpiel & dependencies (TensorFlow, NumPy, Pandas etc.)
- MatPlotLib
- PyTorch
- ABSL-Py